
BeautifulSoupはPythonのライブラリの一つです。
BeautifulSoupを使うことで、HTMLやXML文書をパースすることができます。
Webページのスクレイピングなどを行う際に、タグを探し出し、必要なデータを取り出すことができます。
業務効率化を行いたい方は、BeautifulSoupはとても便利なライブラリです。
今回は、BeautifulSoupで日本語・文字列だけを抽出する方法を解説していきます。
目次
【Python】BeautifulSoupで日本語・文字列だけを抽出する方法

BeautifulSoupで日本語だけを抽出したいのに、余計なものまで抽出されるケースはありませんか?
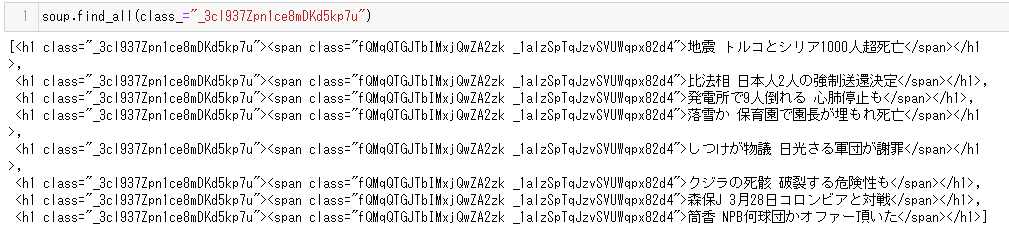
こんな感じでhtmlの情報も出てきてしまいます。
こういう時、日本語の文字列だけを抽出するにはどうしたら良いのでしょうか?
日本語・文字列だけを抽出するコード
BeautifulSoupで取得したデータから、日本語・文字列だけを抽出する方法は以下のとおりです。
soup.find_all(class_="_3cl937Zpn1ce8mDKd5kp7u")[0].text
このようにリスト内の要素に対して、「.text」属性を使用することで、文字列を抽出することができます。
もっと効率的に勉強したい方
独学での勉強に限界を感じている方は、思い切って課金するのも手です。
udemyなら基礎的な知識を短期間でマスターすることが可能です。
僕も最初の頃は、udemyの動画で勉強しました。
講師のコードを見ながら作成できるので、成長速度が非常に早くなりました。
数千円で数十時間の節約になるので、悩んでいる方はケチらず投資していきましょう!







コメント